Inteligência artificial - Classificando casos de câncer como benigno ou maligno
09 Sep 2017
Reading time ~7 minutes
Na graduação me deparei com a disciplina de Inteligência Artificial e para desenvolver o projeto final dela fui procurar por data sets. Logo encontrei um site com uma base de dados incrível e bem variada, o Kaggle.
Navegando achei o Breast Cancer Wisconsin (Diagnostic) Data Set e decidi aplicar meus conhecimentos adquiridos na disciplina nele.
O Data Set
A base de dados possui diversas características físicas de 569 amostras de câncer. São elas:
- Raio (média das distâncias do centro à pontos no perímetro)
- Textura (desvio padrão de valores de escala de cinza)
- Perímetro
- Área
- Suavidade (variação local em comprimentos de raio)
- Solidez (perímetro^2 / área - 1.0)
- Concavidade (severidade das porções côncavas do contorno)
- Pontos côncavos (número de porções côncavas do contorno)
- Simetria
- Dimensão fractal
Para cada um desses atributos a média, o erro padrão e o pior caso foram estabelecidos através de imagens, resultando no total de 30 atributos. Além destes ainda estão presentes o ID do caso e o diagnóstico dado (benigno ou maligno).
O Problema
Sabe-se que por meio dos atributos físicos dos tumores é possível realizar previsões sobre classificá-lo como maligno ou benigno. Para tal é necessário que se tenha domínio sobre o tema e conhecimento de casos prévios. Sabendo disso, a problemática está situada nas seguintes perguntas: É possível obter boas tentativas de classificação de tumores, como benignos ou malignos, a partir de suas características físicas e de forma rápida? Como a tecnologia pode ajudar nisso?
Objetivos
Objetivo Geral
Dada a problemática, o objetivo é trazer a tecnologia para o problema em questão como forma de solução, e utilizar conceitos de inteligência artificial de forma que a classificação possa ser feita com boas taxas de acerto. Estabelecidas essas taxas, compara-se os resultados para determinar o melhor método.
Objetivos Específicos
Inicialmente os dados presentes no dataset serão analisados e preparados para que os métodos de aprendizado de máquina Regressão Logística, Árvore de Decisão, KNN, Random Forest e SVM sejam usados.
Visualização e Tratamento dos Dados
De início, a visualização e o tratamento foram feitos. Constatou-se que a tabela possui 569 linhas, 33 colunas e os dados não se encontram muito desbalanceados, ou seja, a quantidade de casos diagnosticados como benignos não é drasticamente desigual aos diagnosticados como malignos. O que podemos confirmar abaixo, sendo 0 para casos benignos e 1 para malignos:
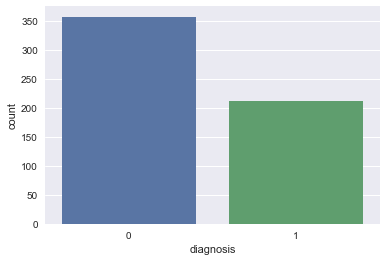
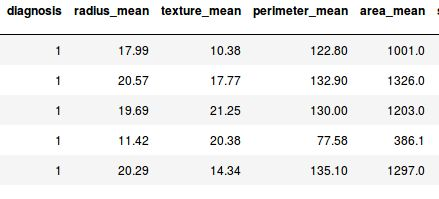
Para manipulação e visualização dos dados foi utilizada a linguagem Python 3.6.1 em conjunto com o pacote NumPy e com o Pandas. Como exemplo de visualização de alguns atributos, temos:
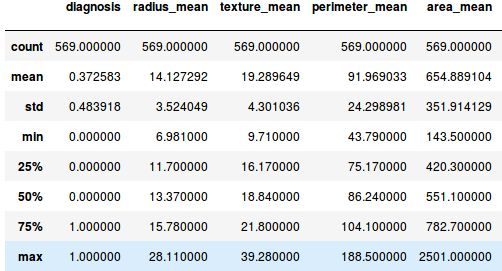
Temos ainda em forma de visualização de algumas estatísticas:
Portanto, como pré-processamento foi feita a visualização dos dados, alterou-se a tabela original retirando o ID dos casos e um atributo chamado Unnamed:32, pois o mesmo não possuía valores em todas as instâncias, ou seja, era uma coluna vazia.
Estudo dos Atributos
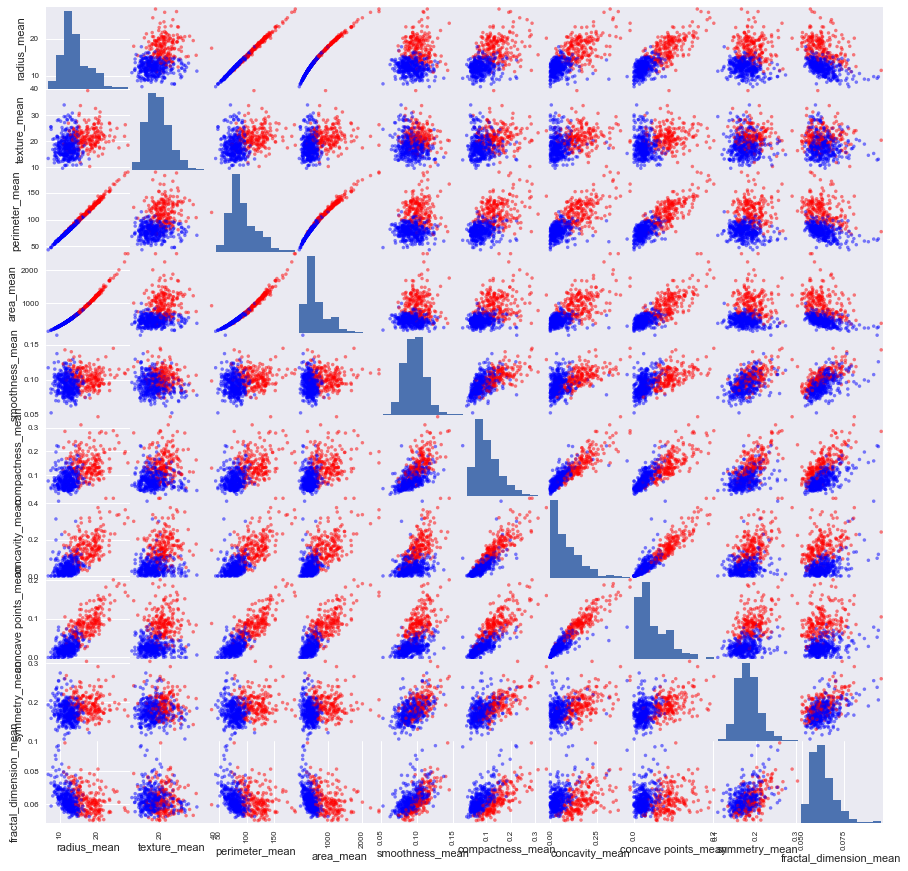
Os atributos de média foram selecionados para serem analisados e utilizamos durante todo o projeto. Nesta etapa foi feita o plot de um scatter plot e de um histograma para a partir deles fazer a verificação dos atributos mais interessantes ao problema. Scatter plot (para melhor visualização basta aproximar a imagem):
Histograma (para melhor visualização basta aproximar a imagem):
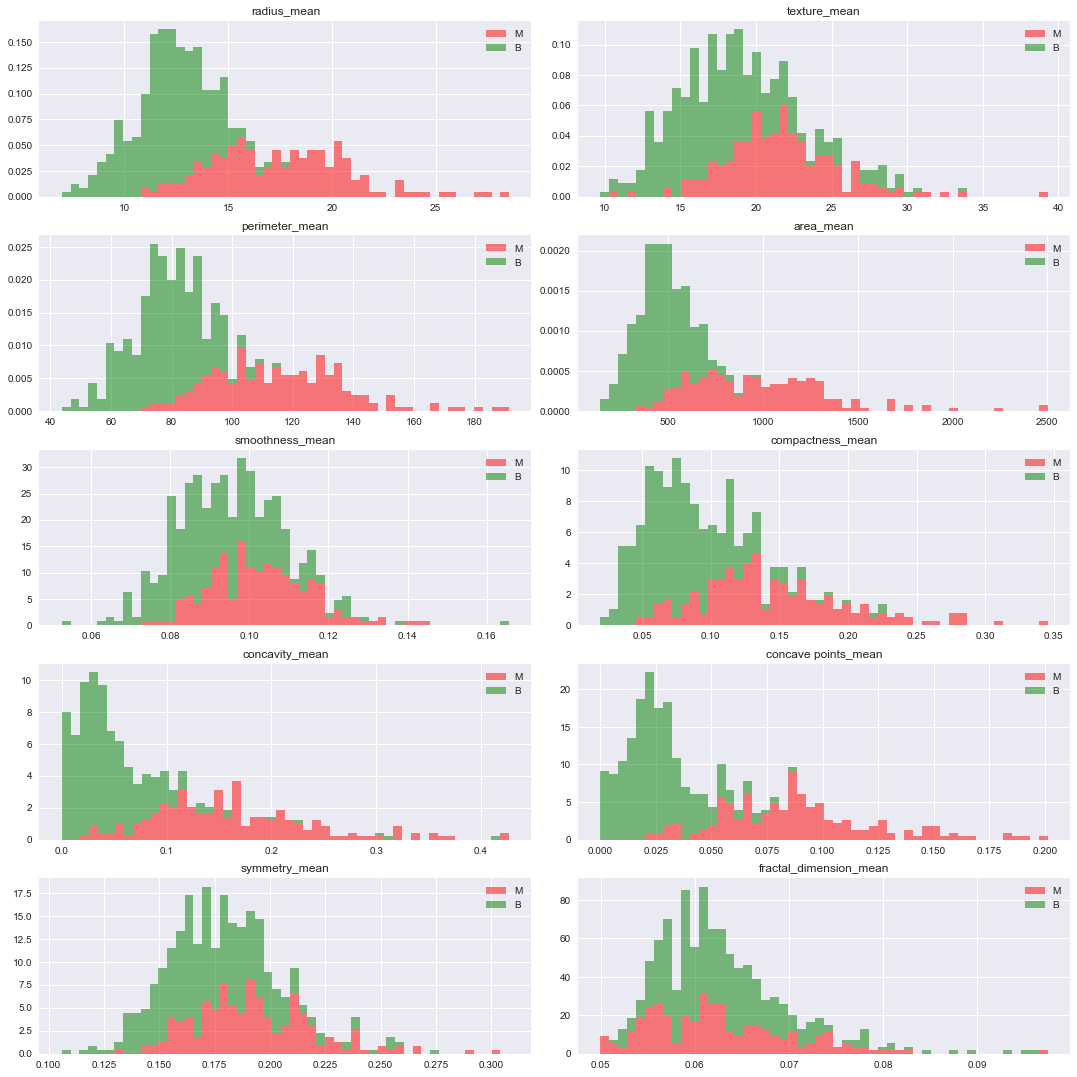
A partir dos gráficos foram feitas as seguintes observações:
- Os atributos radius_mean, perimeter_mean, area_mean, compactness_mean, concavity_mean e concave_points_mean podem ser usados para classificação do tipo de câncer. Valores maiores desses parâmetros tendem a mostrar uma correlação ao tipo maligno.
- Os valores dos atributos texture_mean, smoothness_mean, symmetry_mean e fractal_dimension_mean não demonstram uma preferência particular de um diagnóstico em relação ao outro.
Baseando-se nessas observações, podemos assumir que a classificação do tumor depende dos seguintes atributos/variáveis:
predictor_var = ['radius_mean','perimeter_mean','area_mean','compactness_mean','concavity_mean','concave points_mean']
outcome_var='diagnosis'
data_X= data[predictor_var] # input data
data_y= data["diagnosis"] # output data
Modelo de Classificação
Um modelo de classificação genérico foi implementado para que todos os métodos de aprendizado de máquina usem-o. Para utilizar eles foi usado o pacote sklearn e para encontrar a melhor combinação de parâmetros que resulte no melhor desempenho para o problema, foi usada a função GridSearchCV, do mesmo pacote, que ainda utiliza cross-validation internamente.
from sklearn.model_selection import GridSearchCV
import time
def Classification_model_gridsearchCV(model, param_grid, data_X, data_y):
start_time = time.time()
# busca pela combinação de parâmetros que possui maior acurácia utilizando cross-validation
clf = GridSearchCV(model,param_grid,cv=10,scoring="accuracy")
clf.fit(data_X,data_y) # ajuste do modelo com os parâmetros encontrados
method_score = clf.best_score_*100
processing_time = time.time() - start_time
print("Melhor combinação de parâmetros encontrada:")
print(clf.best_params_)
print()
print("Cross-validation score proporcionada por essa combinação de parâmetros: %s" %"{0:.3f}%".format(method_score))
print("Processing time: %s seconds" % (processing_time))
return method_score, processing_time
Parâmetros da função Classification_model_gridserachCV():
- model = método de classificação a ser testado.
- param_grid = dicionário com todos os valores de parâmetros a serem testados e para que a partir deles a melhor combinação seja obtida.
- data_X = dados de entrada.
- data_y = resultados de saída esperados para o modelo.
O ajuste dos parâmetros é feito pela função fit(), a combinação que gerou melhor desempenho de cross-validation é exibida, a acurácia é medida e também exibida.
Parâmetros da função GridSearch_model_gridsearchCV():
- model = método/modelo.
- param_grid = dicionário de parâmetros.
- cv = cross-validation com divisão dos dados em 10 partes.
- scoring = “accuracy”: pontuação baseada na acurácia.
Regressão Logística
Usa-se a função LogisticRegression() do pacote sklearn no modelo. O conjunto de parâmetros é constituído por alguns valores do parâmetro C para serem testados e o que proporciona o melhor resultado será encontrado. Por fim o modelo de classificação genérico é usado.
from sklearn.linear_model import LogisticRegression
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000] } # valores de parâmetros a serem testados
model = LogisticRegression()
Classification_model_gridsearchCV(model,param_grid,data_X,data_y)
Árvore de Decisão
Para utilizar o modelo de árvore de decisão foi usada a função DecisionTreeClassifier() e foi estabelecido um dicionário de parâmetros para ela para que a melhor combinação dos mesmos seja encontrada. O conceito do dicionário foi utilizado posteriormente também nos demais métodos.
from sklearn.tree import DecisionTreeClassifier
param_grid = {'max_features': ['auto', 'sqrt', 'log2'], # valores de parâmetros a serem testados
'min_samples_split': [2,3,4,5,6,7,8,9,10],
'min_samples_leaf':[2,3,4,5,6,7,8,9,10] }
model= DecisionTreeClassifier()
Classification_model_gridsearchCV(model,param_grid,data_X,data_y)
KNN
Para utilizar o modelo knn foi usada a função KNeighborsClassifier().
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
k_range = list(range(1, 30)) # valores de parâmetros a serem testados
leaf_size = list(range(1,30))
weight_options = ['uniform', 'distance']
param_grid = {'n_neighbors': k_range, 'leaf_size': leaf_size, 'weights': weight_options}
Classification_model_gridsearchCV(model,param_grid,data_X,data_y)
Random Forest
Para utilizar o modelo random forest foi usada a função RandomForestClassifier().
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
params = { "n_estimators": [20,40,60], # valores de parâmetros a serem testados
"max_depth": [3, None],
"max_features": [1,6],
"min_samples_split": [2,6,8,10],
"min_samples_leaf": [1, 3, 10],
"criterion": ["gini", "entropy"]}
Classification_model_gridsearchCV(model,params,data_X,data_y)
SVM
Para utilizar o modelo svm foi usada a função SVC().
from sklearn import svm
model=svm.SVC()
param_grid = [
{'C': [1, 10, 100, 1000], # valores de parâmetros a serem testados
'kernel': ['linear']
},
{'C': [1, 10, 100, 1000],
'gamma': [0.001, 0.0001],
'kernel': ['rbf']
},
]
Classification_model_gridsearchCV(model,param_grid,data_X,data_y)
Análise de Resultados
| Método | Acurácia(%) | Tempo (s) |
|---|---|---|
| Regressão Logística | 90.86 | 0.368 |
| Árvores de Decisão | 92.09 | 8.015 |
| KNN | 89.45 | 108.472 |
| Random Forest | 92.44 | 291.471 |
| SVM | 90.86 | 286.690 |
Um fator que é determinante para o tempo de treinamento neste caso é a possibilidade de combinações de parâmetros testadas, pois todas elas terão que ser usadas para treinamento e posteriormente teste do modelo para então calcular a porcentagem de acerto.
Vemos que três algoritmos que se destacaram para a classificação das instâncias do problema foram Regressão, Árvore de Decisão e Random Forest.
A Regressão Logística obteve o melhor tempo de treinamento, devido à pouca quantidade combinações de parâmetros e foi o vencedor no quesito velocidade de treinamento. Usando Árvore de Decisão temos o segundo melhor tempo com uma porcentagem de acerto muito próxima ao melhor algoritmo desse quesito, que foi o Random Forest, sendo portanto um algoritmo de ótimo custo benefício para o problema. E o Random Forest foi o vencedor no quesito acerto ficando bem atrás de seus concorrentes em relação ao tempo necessário de processamento.
Conclusão
Neste projeto foram utilizadas diferentes abordagens para classificar casos de câncer de mama como benigno e maligno realizando um estudo dos atributos presentes no dataset. Algoritmos diferentes foram usados, tais como, Regressão Logística, Árvore de Decisão, KNN, Random Forest e SVM, respeitando as particularidades dos parâmetros de cada um deles.
Vale ressaltar que os desempenhos obtidos por eles são considerados bons ou ótimos e pode-se destacar a Regressão Logística, Árvore de Decisão e Random Forest pelos seus resultados. Esses em especial mostraram que podem estar à disposição de pessoas que possuem o desejo de unir o que a tecnologia proporciona e a necessidade de entender melhor os problemas que vivemos, assim como o problema de classificação correta de um tumor.
Repositório do Github
Acesse o repositório no Github contendo toda a implementação e um relatório mais detalhado aqui.